
I’m a final-year Ph.D. candidate in Computer Science at UIUC, advised by Prof. Shenlong Wang and Prof. Alex Schwing.
My research focuses on digital avatars, with an emphasis on efficient, photorealistic, and animatable avatar reconstruction, as well as motion understanding.
Before joining UIUC, I received my Master of Language Technologies from CMU and B.Eng. in Computer Science and Technology from Tsinghua University.
Check my latest Curriculum Vitae here.
Publications

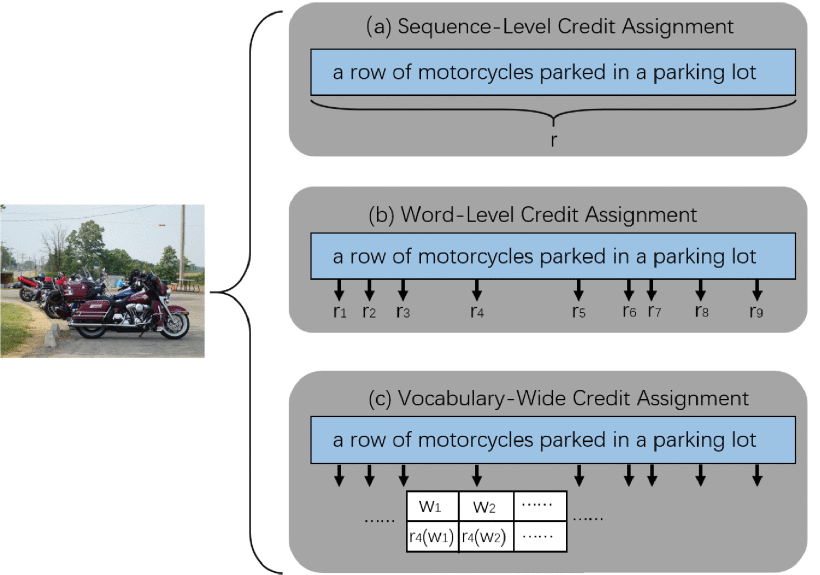
Vocabulary-Wide Credit Assignment for Training Image Captioning Models
Transactions on Image Processing (TIP) 2020
Internships

Research Scientist Intern @ Meta Reality Labs
Project: Time-consistent Controllable Human Animation with Diffusion Models
Mentors: Dr. Stephane Grabli, Dr. Yuanlu Xu, Dr. Tony Tung, Dr. Bharat Bhatnagar and Dr. Emanuel Garbin

Engineering Practicum Intern @ Google
Project: Boq and Apps Framework based Mobile Harness Front End V5
Mentors: Mr. Keyi Gui and Mr. Wenshan Fu